准备资源文件
我们安装 WebUi 有两个途径,一是哔哩哔哩 Up 主秋叶的一键包,二是原生从仓库拉取安装。前者较适合中国大陆用户。
请保证你的文件夹/路径里面没有中文,否则涉及 Git 的更新/安装操作会失败。
准备环境
在开始之前,你需要以下条件。
-
一个 Windows、Linux 或 MacOS 的操作系统
-
一个安装了 Git、Python 和 Wget 的环境
-
一个有足够空间(至少 30~40GB)的磁盘或目录
-
一张至少 4GB 显存的显卡
-
剩余足够 10GB 的内存(WebUi 使用过程中会逐步增加内存占用)
对于 Linux 系统,您可能已经预装了 git 和 wget 工具。您可以在终端中运行以下命令来检查它们的版本:
git --version
wget --version
如果没有预装它,可以使用 apt 或 yum 等包管理器来安装它们。例如,对于 Ubuntu 系统,可以运行以下命令:
sudo apt update
sudo apt install git wget
对于 Windows 系统,您可能需要下载并安装 git 和 wget 的可执行文件。可以从这些链接下载它们:
https://git-scm.com/download/win
http://gnuwin32.sourceforge.net/packages/wget.htm
准备程序
一键包下载地址及介绍
如果整合包里面没有大模型的话(models 文件夹),可以翻查下面的链接下载一个,放入 sd-webui 启动器、数据整合包、models\Stable-diffusion 即可,如果有 vae 模型一并放入,否则生成的图片会灰蒙蒙的。
WebUi 原生安装
如果你是 Windows 用户,请做好 C 盘暴涨 15GB 的准备。
Linux 平台
先安装依赖
# Debian-based:
sudo apt install wget git python3 python3-venv
# Red Hat-based:
sudo dnf install wget git python3
# Arch-based:
sudo pacman -S wget git python3
使用conda控制环境
如果本地包含多个项目,需要多种Python环境,可以使用 Miniconda 进行环境管理。( Anaconda 占用较大的系统空间,而 Miniconda 是 Anaconda 的轻量化版本,它只包含最基本的 Python 与 Conda )
# 创建一个名为 aidraw 的环境,Python版本为3.10.6
conda create -n aidraw python=3.10.6
# 激活/使用这个conda环境
conda activate aidraw
# 首次启动可选参数,--medvram 参数节省一些显存占用(参数详见下文“自定义运行”)
COMMANDLINE_ARGS="--medvram" REQS_FILE="requirements.txt" python launch.py
你也可以运行一键脚本 bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh) 或者手动克隆 https://github.com/AUTOMATIC1111/stable-diffusion-webui 的仓库:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd stable-diffusion-webui
运行 launch.py 或 webui.py ,前者会自动安装(新)环境。
这个过程可能需要一些时间,请耐心等待。
Windows 平台
首先,您需要下载安装 Python-3.10.6,使用管理员身份安装,安装务必勾选 Add Python to PATH 。
然后安装 git 下载 stable-diffusion-webui 仓库,例如运行 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git 在 Windows 资源管理器中以普通用户(非管理员)身份运行 webui-user.bat
然后,您需要进入这个文件夹,并运行 webui-user.bat(Windows)
这个过程可能需要一些时间,请耐心等待。
Mac 平台
如果你是 Mac 系统,请查看 此教程 进行安装。
具体使用和输出我会在下面解释,现在该配置大模型了。
中国大陆的网络问题
如果你在大陆内采用了原生安装的形式安装 WebUi,那么势必会遇到网络问题。(表现为网卡没有流量经过)
如果你知道 Clash 工具,那么在首页开启 TUN 模式即可解决问题。如果你不了解此工具,请继续往下看。
如果因为链接 Github 失败导致拉取失败。请将:
git clone https://github.com 改为 git clone https://hub.fastgit.org/
使用以下内容配置 Python 镜像地址。
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
也可以通过修改 pip 的配置文件来设置镜像源地址,配置文件的位置和名称根据不同的操作系统而不同,例如:
Linux: ~/.config/pip/pip.conf:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
Windows 需要在 User 目录中创建一个 pip 目录,并新建一个文件 pip.ini,也就是 %HOMEPATH%\pip\pip.ini。 在 pip.ini 文件中添加以下内容:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
了解目录
📁 .
├── 📄 config.json
├── 📄 environment-wsl2.yaml # Windows Subsystem for Linux 的环境配置
├── 📁 extensions
│ ├── 📄 put extensions here.txt
│ └── 📁 stable-diffusion-webui-localization-zh_CN
├── 📄 launch.py
├── 📄 LICENSE.txt
├── 📁 models # 存储各类模型的目录
│ ├── 📁 aesthetic_embeddings # 美学嵌入模型
│ ├── 📁 Codeformer
│ ├── 📁 deepbooru # 深度图库标签分类模型
│ ├── 📁 ESRGAN # 增强超分辨率生成对抗网络模型
│ ├── 📁 GFPGAN # 基于 GAN 的人脸修复模型
│ ├── 📁 hypernetworks # 超网络模型
│ ├── 📁 LDSR # 轻量残差网络模型
│ ├── 📁 Lora # Lora 模型
│ ├── 📁 ScuNET
│ ├── 📁 Stable-diffusion # 稳定扩散模型
│ ├── 📁 SwinIR # 轻量级基于 Swin Transformer 的增强超分辨率模型
│ ├── 📁 VAE # 变分自编码器模型
│ └── 📁 VAE-approx # 变分自编码器的近似计算模型
├── 📁 outputs # 存储各类输出结果的目录
│ ├── 📁 img2img-grids # 由图生图模型生成的网格图(2x2)
│ ├── 📁 img2img-images # 由图生图模型生成的图像
│ ├── 📁 extras-images # 额外的生成图像
│ ├── 📁 txt2img-grids # 由文本生图模型生成的网格图(2x2)
│ ├── 📁 txt2img-images # 由文本生图模型生成的图像
│ └── ... # 其他目录
├── 📁 repositories # 目录缓存
├── 📄 requirements.txt # pip项目依赖
├── 📄 style.css
├── 📄 styles.csv
├── 📄 styles.csv.bak
├── 📄 ui-config.json
├── 📄 webui.bat # Win 运行脚本
├── 📄 webui-macos-env.sh # macOS 默认环境配置
├── 📄 webui-user.bat # Windows 启动用户脚本配置
├── 📄 webui-user.sh # Linux & Mac 启动用户脚本配置
├── 📄 webui.py
└── 📄 webui.sh # Linux & Mac 运行脚本
webui.bat。若需要配置环境变量或追加启动参数,则可编辑 webui-user.bat。
对于 Mac 或 Linux 用户,启动项目的方法是执行 webui.sh。同样地,若需要配置环境变量或追加启动参数,则可编辑 webui-user.sh。
配置大模型
让 Ai 绘画必须下载一个模型(比如 AnythingV5),你可以在 civitai 选择一个。WebUi 界面顶部的菜单用于选择模型。
你可以在 stable-diffusion-webui/models/Stable-diffusion/ 中放置你的大模型。
在 stable-diffusion-webui/models/Lora/ 中放入你的 Lora 人物模型。
尝试启动 WebUi
如果你不使用一键启动运行。那么你可以使用以下命令启动 Webui
python3 launch.py --autolaunch
如果你的显卡显存小于 8GB ,那么请附加 --lowvram 参数。
经过稍微的等待后,会输出如下类似的界面。
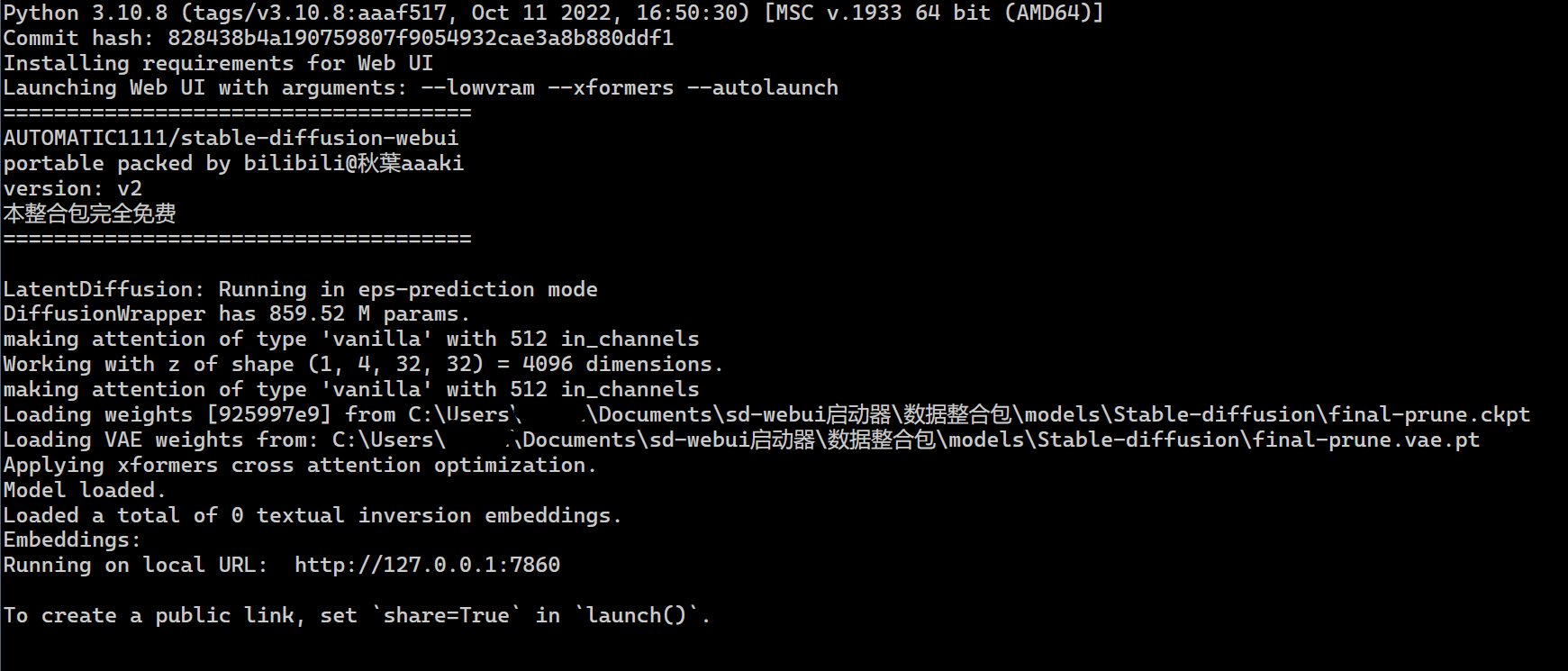
Model loaded.
Loaded a total of 0 textual inversion embeddings.
Embeddings:
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`
http://127.0.0.1:7860 就是本地机器的链接(运行在本地机器上面),剩下的信息是大模型和嵌入模型的加载情况。
打开此地址,你会看到下面的界面:
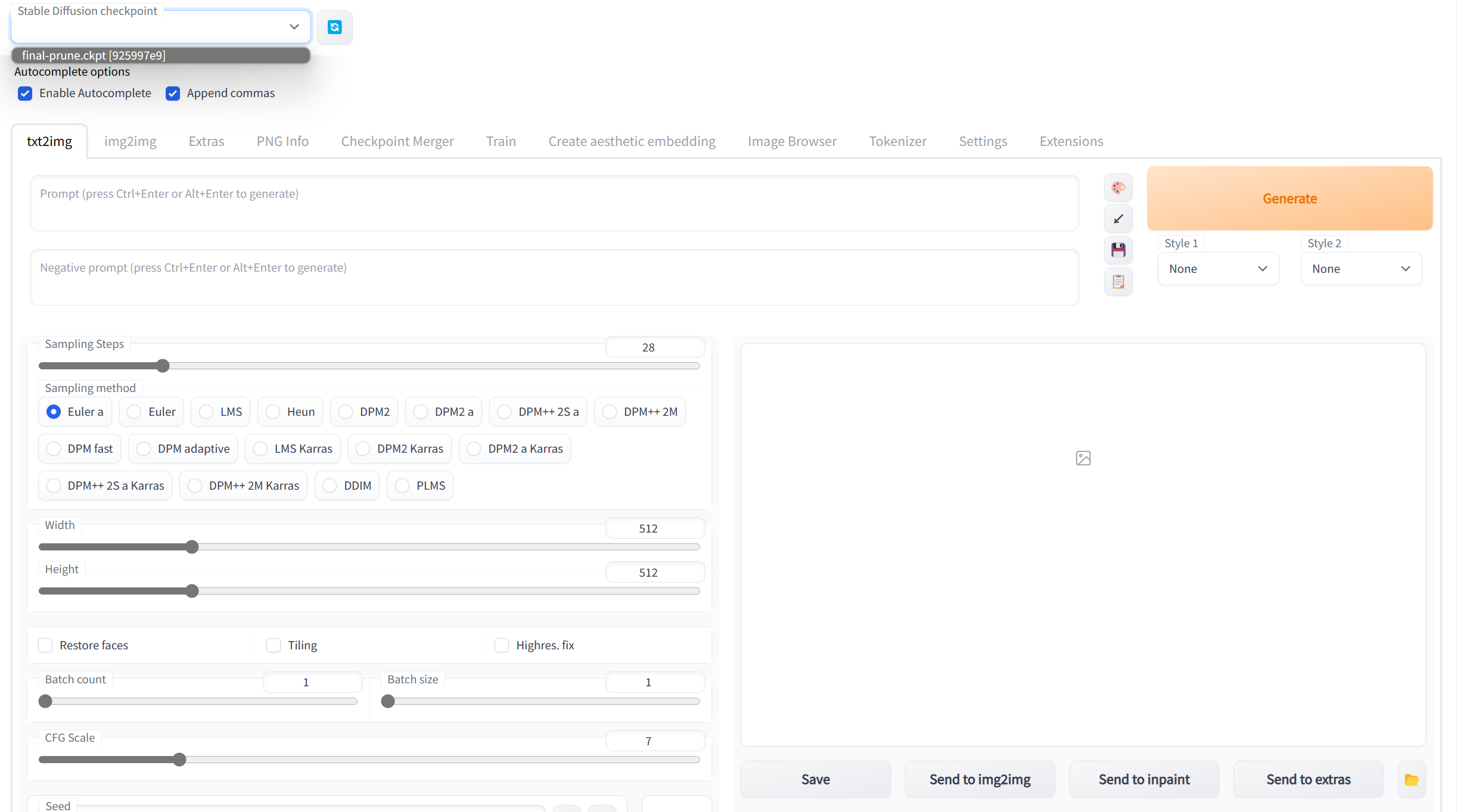
在这个界面中,打开 extensions 选项卡。点击Avaliable二级选项卡点击 LoadFrom,然后在扩展列表中找到中文扩展并安装即可汉化界面。如果你是一键包版本,那么应该会自带中文扩展。
尝试生成你的第一幅图片
打开文生图选项卡,这里给出一个实例来供你完成测试。
- 第一个输入框中书写期望的结果的描述词汇
可以使用 颜文字 和 emoji,使用 () 来增强权重,比如
((masterpiece)), best quality, illustration, 1 girl, beautiful,beautiful detailed sky, catgirl,beautiful detailed water, cinematic lighting, dramatic angle, Grey T-Shirt, (few clothes),(yuri),(medium breasts),white hair,cat ears,masturbation,bare shoulders ,(gold eyes),wet clothes
- 第二个输入框书写不希望出现的结果
指定需要过滤什么标签,比如
(bad:0.98), (blur:0.81), (normal:0.98), (comic:0.81), (cropped:0.81), (error:0.81), (extra:0.81), (low:0.81), (lowres:1), (speech:0.81), (worst:0.81), 2koma, 3koma, 4koma, collage, lipstick
点击生成按钮即可生成,在终端中会显示进度:
生成报错请读 绘画调试 章节。
生成效果和大模型有关。
第一次认识参数
选定分辨率参数,越大生成耗时越长。
生成后的结果结尾类似如下
Steps: 28, Sampler: Euler a, CFG scale: 7, Seed: 2053144181, Size: 512x512, Model hash: 925997e9, Clip skip: 2, ENSD: 31337
其中 step 代表迭代(渲染)步数。
sample method 采样方法(不同的采样方法有不同的效果和速度)。
cfg scale 符合 prompt 的程度,降低此参数可以提升模型的抽象创造力。
Seed 代表一个随机噪声,相同的种子和程序环境可以生成相近的图片。
一起出现的还有 GPU 负载信息
Time taken: 33.97s
Torch active/reserved: 1975/2144 MiB, Sys VRAM: 7890/8134 MiB (93.61%)
快捷设置
不想来回设置 Clip 参数?
添加 sd_hypernetwork 和 CLIP_stop_at_last_layers 到设置页面的 Quicksettings list ,点击页面顶部的按钮保存,重新启动 webui,你就可以在 Ui 顶部看到一个快速切换选项啦~
共享链接
- 使用
--share选项来在线运行!
你会得到一个 xxx.app.gradio 共享链接,另外你可以使用参数为所述 gradio 共享实例设置身份验证:--gradio-auth username:password
RCE
当使用 --share 参数时,你的实例就可以在公开互联网被访问了。
但是最近有人报告了一个可能是危险的 代码漏洞
所以,你可以使用参数为 gradio 共享实例设置身份验证:--gradio-auth username:password (可提供以逗号分隔的多组用户名和密码)
例子
--share --gradio-auth admin:admin,user1:user_password
使用该例子将会创建两个用户,一个是账号密码为 admin 的用户,另外一个是账号为 user1, 密码为 user_password 的用户
如果攻击者可以访问 ui,他们可能能够远程运行 python 脚本。
10/30 社区报告:有人在扫描公开的 WebUi
11/1 社区反映:共享链接可能会导致风险,攻击者可以访问系统上的所有文件。
你可以通过添加 --freeze-settings 启动参数来锁定设置,防止他人编辑。
- 端口转发
参数 --listen 使服务器监听网络连接。
这将允许本地网络上的计算机访问 UI,如果配置端口转发,公网上的计算机也可以访问(当然你得有公网。
注意,监听 0.0.0.0 就意味着对本地网卡的所有 ipv4 监听,局域网访问请使用 localhost 替换 0.0.0.0
- 监听端口
添加参数 --port xxxx 使服务器监听特定端口。
低于 1024 的所有端口都需要 root 权限,因此建议使用高于 1024 的端口。
默认端口为 7860
- 主题
添加 --theme 参数来切换主题
自定义运行
自定义程序运行方式的推荐方法是编辑 webui-user.bat(Windows) 和 webui-user.sh(Linux)
你可以运行 python webui.py --help 查看所有命令参数,或者在 源码文件 中读到它们。
一些启动参数说明
| 命令行参数 | 解释 |
|---|---|
--xformers |
使用 xformers 库。极大地改善了内存消耗和速度。Windows 版本安装由 C43H66N12O12S2 维护 的二进制文件 |
--force-enable-xformers |
无论程序是否认为您可以运行它,都启用 xformers。不要报告你运行它的错误。 |
--opt-split-attention |
Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。 |
--disable-opt-split-attention |
禁用上面的优化 |
--opt-split-attention-v1 |
使用上述优化的旧版本,它不会占用大量内存(它将使用更少的 VRAM,但会限制您可以制作的最大图片大小)。 |
--medvram |
通过将稳定扩散模型分为三部分,使其消耗更少的 VRAM,即 cond(用于将文本转换为数字表示)、first_stage(用于将图片转换为潜在空间并返回)和 unet(用于潜在空间的实际去噪),并使其始终只有一个在 VRAM 中,将其他部分发送到 CPU RAM。降低性能,但只会降低一点-除非启用实时预览。 |
--lowvram |
对上面更彻底的优化,将 unet 拆分成多个模块,VRAM 中只保留一个模块,破坏性能 |
*do-not-batch-cond-uncond |
防止在采样过程中对正面和负面提示进行批处理,这基本上可以让您以 0.5 批量大小运行,从而节省大量内存。降低性能。不是命令行选项,而是使用--medvramor 隐式启用的优化--lowvram。 |
--always-batch-cond-uncond |
禁用上述优化。只有与--medvram或--lowvram一起使用才有意义 |
--opt-channelslast |
更改 torch 内存类型,以稳定扩散到最后一个通道,效果没有仔细研究。 |
环境定制
set PYTHON=b:/soft/Python310/Python.exe
set PYTHON 允许设置自定义 Python 路径
set VENV_DIR=C:\run\var\run
set VENV_DIR 允许您选择虚拟环境的目录。默认为venv。特殊值-在不创建虚拟环境的情况下运行脚本。
set COMMANDLINE_ARGS=--ckpt a.ckpt
set COMMANDLINE_ARGS 设置命令行参数 webui.py 运行
示例使用模型 a.ckpt 而不是 model.ckpt
GPU 指定
选择要使用的默认 Gpu --device-id 0,来代替旧版本 (2022/10 之前)的 CUDA_VISIBLE_DEVICES=0,可以选择第二个 GPU 允许同时运行两个实例,从而能够以更简洁的方式简单地选择设备。
查看 GPU 型号和 CUDA 版本,可以使用 nvidia-smi 命令
API 的基本使用实例
使用 --api 参数运行程序,在浏览器访问 {输出的网址}/docs 就可以查看到 WebUi 的 Api 文档。1
如果你想让其他应用调用 Api, 追加--enable-insecure-extension-access。
下面是一个同步类实现。
import time
import json
import requests
import io
import base64
from PIL import Image, PngImagePlugin
class WebUiApi(object):
def __init__(url):
self.url=url
def txt2img(payload,outpath:str=None,infotie:bool=True):
payload_json = json.dumps(payload)
response = requests.post(url=f'{self.url}/sdapi/v1/txt2img', data=payload_json).json()
# response 响应包含 images、parameters 和 info,image 可能会含有多个图像。
for i in response['images']:
# 解码 base64
image = Image.open(io.BytesIO(base64.b64decode(i)))
# 元信息输出
pnginfo = PngImagePlugin.PngInfo()
if infotie:
pnginfo.add_text("parameters", str(response['info']))
# 保存,因为本地不会自动生成文件。
if not outpath:
print("Random file name")
outpath=f"{str(time.time())}.png"
image.save(outpath, pnginfo=pnginfo)
payload = {
"prompt": "1girl,star",
"steps": 20
}
# 其他参数会使用默认值
WebUiApi(url="http://127.0.0.1:7860").txt2img(payload=payload,outpath="1145.png",infotie=True)
# 实际使用的时候不应该保存到本地再发送,而是直接发送,避免存储图片作品造成 版权 问题。
其他
WebUi 的官方代码仓库地址为 https://github.com/AUTOMATIC1111/stable-diffusion-webui