DreamBooth
简介
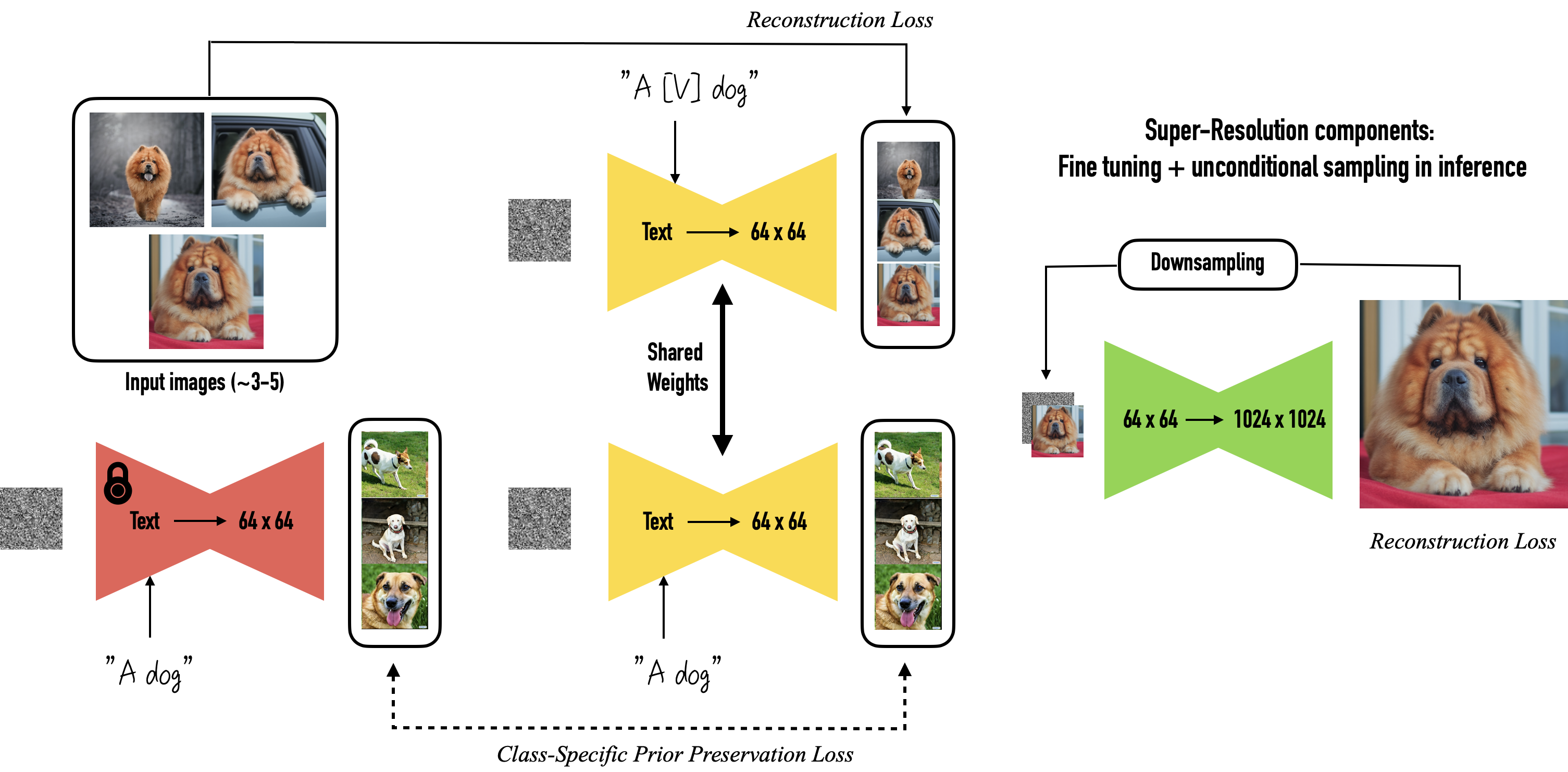
DreamBooth 是一种定制个性化的 TextToImage 扩散模型的方法。仅需少量训练数据就可以获得极佳的效果。
Dreambooth 基于 Imagen 研发,使用时只需将模型导出为 ckpt,然后就可以被加载到各种 UI 中。
然而,Imagen 的模型和预训练的权重都不可用。所以最初的 Dreambooth 并不适用于稳定扩散。但后面 diffusers 实现了 Dreambooth 这一功能,并且完全适配了 Stable Diffusion。
Diffusers 提供跨多种模态(例如视觉和音频)的预训练扩散模型,作为扩散模型推理和训练的模块化工具箱提供支持。
本节使用的是 Shivam Shirao 的 diffusers 分支版本讲解参数,配置衍生自 ShivamShrirao/diffusers。
推荐使用 CCRcmcpe 的针对 Stable Diffusion 的 优化分支, 可以使用 Yaml 文件。
by https://dreambooth.github.io/
选择
Windows 系统的显存至少需要 16GB, Linux 系统要求显存至少为 8GB。
-
适用于 喜欢 Yaml 文件配置 的 CCRcmcpe/diffusers/ 分支,可以使用 Yaml 文件进行配置。
-
适用于 AutoDl/本地 的 DreamBooth 版本,由 Kurosu Chan 提供
-
适用于 AutoDl/本地 的 封装镜像,名称为
dreambooth-for-diffusion,但是缺乏维护。 -
适用于 WebUi 的 插件,但是仍待加强。
-
适用于 Colab 的 Nyanko Lepsoni 的 Colab 笔记本, 由 Nyanko Lepsoni 提供。
-
适用于 Colab 的 RcINS 的 Colab 笔记本 由 RcINS (https://t.me/StableDiffusion_CN/196744) 提供。
Colab 笔记本来自 社区置顶
准备
AutoDl
如果你选择使用 AutoDl 的镜像,需要把 dreambooth-for- diffusion 文件夹移到 autodl-tmp(数据盘)中,且确保运行路径 (# 前面的那一串)为 dreambooth-for-diffusion,具体操作细节在 知乎教程 中有图文说明。
模型转换
在各个笔记本或镜像中都会有以下类型命令,作用是将 ckpt 模型转换为 diffusers 权重格式来训练。
- 训练前示例
python diffusers\scripts\convert_original_stable_diffusion_to_diffusers.py --checkpoint_path model.ckpt --original_config_file v1-inference.yaml --scheduler_type ddim --dump_path models/diffusers_model
- 训练后示例
训练完成后,打包转换为 ckpt 即可用于各种 UI 中。
python diffusers\scripts\convert_diffusers_to_original_stable_diffusion.py --model_path models/resultModel --checkpoint_path result.ckpt --half
数据集
数据集的创建是在 Dreambooth 训练 中获得良好、稳定结果的最重要部分。3
class 和 instance 的质量决定生成的质量。
- 内容要求
一定要使用高质量的样本,运动模糊或低分辨率等内容会被训练到模型里,影响作品质量。
当为一个特定的风格进行训练时,挑选具有良好一致性的样本。理想情况下,只挑选你要训练的艺术家的图像。避免粉丝艺术或任何具有不同风格的东西,除非你的目标是像风格融合。
对于主题,黑色或白色背景的样本有极大的帮助。
透明的背景也可以,但有时会在主体周围留下白色轮廓,所以目前我不建议使用透明背景。
如果需要使你的 Dreambooth 模型更加多样化,尽量使用不同的环境、灯光、发型、表情、姿势、角度和与主体的距离。
请确保包括有正常背景的图片(例如,对象在一个场景中的图片)。只使用带简单背景的图片,效果会比较差。
避免在你的渲染图中出现手粘在头上的情况,请删除所有手太靠近或接触头部的图片。
如果需要避免渲染图中出现鱼眼镜头效果,可以删除所有自拍图片。
为了避免不自然的过度模糊,确保图像不包含假的重景深或虚化。
- 调节
一旦你收集了数据集的照片,将所有图片裁剪并调整为 512x512 的正方形(你可以利用 BIRME 在线工具批量裁剪),并删除任何水印、商标、被图片边缘切断的人/肢体,或其他你不希望被训练的内容。以 PNG 格式保存图像,并将所有图像放在 train 文件夹中。
Augmentation
处理图片的方式有许多,常见的有反转,旋转,亮度和裁切。将图片打碎或者对背景/大头等单独裁切,也许有助于提高训练效果。
相关实例请参考 Diffusers ベースの DreamBooth の精度をさらに上げる・ augmentation 編 .
It may be useful to break up the image, or to crop the background/headers etc. separately.
参数
先让我们看一下来自 CCRcmcpe diffusers 版本 的 Yaml 配置文件。
DreamBooth 本身不能训练所谓的画风。而 Native Training 对模型进行微调会带来画风的改变,作为所谓的画风训练方法。
古典思路是:
Native + deepdanbooru->prompt txt - “训练风格”
Dreambooth + class prompt/instance prompt - 训练物体
但还有很多分类,差异如:是否给每张图片配对 Prompt, 是否 启用 prior_preservation loss(PPL), 是否使用 train text encoder (TTL)4
DreamBooth = instance + class with prior preservation loss (其中分给图片单独标签,和使用同一个标签的区别)。
DreamBooth
专业训练特定物体/人物。使用 --with_prior_preservation 来启用 DreamBooth ,只有 DreamBooth 训练会用到 [V] 的概念和 --instance_prompt 相关的参数。
-
Instance Image 你所训练的对象
-
Instance Prompt 默认实现为全局共享一个 prompt, 这对于 few shot 是可能有效的,即 DreamBooth (original paper method)。但当你的训练目标增多之后可以开启
combine_prompt_from_txt选项,为每个 instance 准备一个 prompt (通常为 txt) 即为 DreamBooth (alternative method). Instance Prompt 之中应该包含一个唯一标识符 [V]. 详细解释见后。4 -
Class/Regularization Image 对应
--class_data_dir,应该为 自动生成 即 auto-generated 的图像,用于检测 AI 的先验知识。不应该放任何非 AI 生成的图像。(如果你确定这么做为什么不去使用 Native Training 呢?)掺杂同风格图在 clas image 已经不再鼓励。每次重新训练不同主题要清空一次。 -
Class Prompt 对应
--class_prompt参数,由程序自动生成,可以从其他支持 CLIP SKIP 2 的推理前端生成好之后放进 class img 内。程序同样可以从独立的 txt 中读取内容。4
DreamBooth 本身具有十分强烈的 copy and paste 效果,使用 class/regularization 可以适当抑制该效果。4
训练多个物体请读 Multiple Concept 节。
Native Training
Native Training 为原生训练,与 DreamBooth 不同的是,Native Training 会直接使用你的训练集进行训练,不再需要 Class Image.
关闭 prior_preservation 选项以开始以原生方式进行训练,是“训练画风”的推荐方式。
在此训练中没有 Instance/Class Image 之分,所有的图都会被用于训练。但是你需要为每个图准备一个 Instance Prompt, 放在和图片名称一样的文本文件,通常为 txt,例子参考 dataset exp
后续通过启用 --use_txt_as_label 来读取这个与图片同名的 txt 文件作为 label(该选项会无视 instance_prompt 参数传入的内容)。
Native Training 需要 较多 的数据集,但这个量众说纷纭,大约在 [100, 10000] 这个区间,多多益善 (但仍然建议人工挑选)
参数
- with_prior_preservation
启用 prior_preservation 以开始 DreamBooth 训练,禁用此参数来开启 Native Training。
- prior_loss_weight
- learning_rate
学习率
- use_txt_as_label
通常在 Native 训练微调模型时使用。读取与图片同名的 txt 文件作为 label。启用该选项会关闭 DreamBooth, 无视 instance_prompt 参数传入的内容而转为从 txt 文件中读取 label。
- center_crop
脚本自带的裁切图片选项,建议自己裁成正方形的哦。
- resolution
图片的分辨率(一般为 512),定义此参数会缩放图像。
- max_train_steps
训练的最大步数,一般是 1000,如果你的数据集比较大,那么可以适当增大该值。
训练步数的选择一般来说是,训练步骤 =(参考图像 x 100)
- save_model_every_n_steps
每多少步保存一次模型,方便查看中间训练的结果找出最优的模型,也可以用于从检查点恢复上一次的训练结果(colab 笔记本用户注意挂载到云盘中)。
- lr_scheduler
学习率调节器,可选有 constant, linear, cosine, cosine_with_restarts, cosine_with_hard_restarts
解释 Instance Prompt / Class Prompt
class prompt 会用来生成一类图片,被处理为类似 photo of a person
instance prompt 会被处理为类似 photo of a cute person
训练人物的示例
- Instance prompt:
masterpiece, best quality, sks 1girl, aqua eyes, aqua hair - Class prompt:
masterpiece, best quality, 1girl, aqua eyes, aqua hair
训练风格的示例
- Instance prompt:
1girl, by sks - Class prompt:
1girl
关于 [V]
| 训练集类型 | Instance prompt 必须包含的 | Class prompt 应该描述的 |
|---|---|---|
| 物体/人 | [V] |
物体的类型和/或特征 characteristics |
| 艺术家风格 | by [V] |
训练集的共同特点 |
[V] 只用在 Instance prompt 中,是 CLIP 词汇表中的标记,对模型没有意义。这是由你自己设定的短语,类比方程未知量 x,不是一个叫 [V] 的确切值。
假设你想训练的人物叫做 [N](比如 balabalabala 先生) , 你不应该直接使用 [N](balabalabala 先生) 作为代表特征词。4
推荐使用在 该词汇表 中存在但是没有对应概念或者说对应概念不明显的词 [V](比如 bala)。
非常长的名称很可能被分离为多个标记,会得不到预期效果。标记的分离情况具体可在 NovelAI Tokenizer 验证。
最后代表 [V] 的提示将携带模型学到的新东西,你就可以在生成时使用你设定的 [V] 了。
注:原论文中使用的示例词
sks和现实中的枪械 SKS 相同,属于不适合被使用的词汇。但是如果你的训练程度足够高的话说不定可以覆写其影响。
TIPS:不要使用默认的 by sks(sks 这个艺术家), 融合模型的时候会发生灾难。
解释 Subject images / Class images
介绍来自 2
Subject images (或者你在笔记本上看到的实例图像)是你想要训练的图像,所以如果你想要自己的外观的模型,你可以取 20 到 40 张自己的图像并输入这些图像。实例名是一个唯一的标识符,它将在提示符中表示受训对象,个人使用 “namelastname”,大多数笔记本使用“sks”,但最好更改它。
你实际上是在告诉 AI 把你介绍到数据库中,为了做到这一点,你选择一个类别,即最适合你所训练的类别,对于人们来说,通常使用 "person", "man"/"woman" 等。
在训练中使用 Class images 是为了 防止物体的特征 “渗透” 到同一 Class 的其他物体中。如果没有 Class images 作为参考点,AI 会将你的脸与 Class 中出现的其他脸合并。你的脸会渗透进模型生成的其他脸中。
DreamBooth 可以在没有 Class images 的情况下开始训练,只需要禁用 --with_prior_preservation 来开启 Native Training.
Native Training
Native Training 为原生训练,与 DreamBooth 不同的是,Native Training 会直接使用你的训练集进行训练,不再需要 Class Image.
关闭 prior_preservation 选项(也就是 --with_prior_preservation 参数)以开始以原生方式进行训练,是训练画风的推荐方式。
在此训练中没有 Instance/Class Image 之分,所有的图像都会被用于训练。但是你需要为每个图准备一个 Instance Prompt, 就像传统的 hypernetwork 一样同文件名称,通常为 txt.
关于这个 Txt
对于数据集中的每张图片([X].png/[X].jpg),再放一个包含相应提示的 [X].txt。然后设置 READ_PROMPT_FROM_TXT( --use_txt_as_label )。Both train set and class set supports this.
从 txt [PX] 中读取的提示将被插入到你在训练参数中设置的提示 [P] 中。默认情况下,它的插入方式是 [PX][P]。
在启用 Variable Prompts 和禁用先前保存损失 (PRIOR_PRESERVATION) 的情况下,训练过程实际上等同于标准微调。
Native Training 需要较多的数据集,但这个量众说纷纭,大约在 [100, 10000] 这个区间,多多益善。(建议人工挑选)
标注方法
你可以手动标注或使用 clip 或 deepdanbooru 进行自动标注。
推荐使用 crosstyan/blip_helper 去给你的图像打标。或者使用 DeepDanbooru 和 BLIP
如果你使用 AutoDl 的镜像,你可以使用内置的 label_images.py 进行标注。
从检查点恢复训练
参数的 MODEL_NAME 改成上一次模型的位置。
如果你用到 CLASS_DIR ,因为主题相同,所以不必清空,反之则清空。
Train Text Encoder
对应实例中的 --train_text_encoder,不推荐使用。使用 --train_text_encoder 后,Dreambooth 训练会额外训练文本编码器,会让不同模型之间的 prompt 无法通用。
有玄学说法是在达到训练的某个百分比/epoch/step 之后应该关闭以防止过度玩坏。
- 一开始写的 instance prompt 要长一些,概括你的训练目标 (但是又不要太长,不要覆盖你常用的词) (像是 girl 我会换成 woman, 1boy 换成 male)
- text prompt 词数太多了影响分散,效果不明显。
- instance prompt 不能只填一个
[V](比如balabala,应该是a photo of balabala) ,否则那个词也废掉了。 - 尝试提高学习率
炼出来调用的话看情况加你训练的 instance prompt 的词,看你想要多少味道。
或许训练人物的时候也是效果拔群。
Multiple Concept
对应实例中的 --concept_list 参数,用 DreamBooth 是可以训练多个概念/人物/动作/物体的。但是若训练两个人物则推理时不能使其同时出现,两者的特征会被混合起来。
如果用其他版本的 DreamBooth 训练方法检查 --concept_list 参数,可以读入一个类似的 json 文件。
- concepts_list.json
# You can also add multiple concepts here. Try tweaking `--max_train_steps` accordingly.
concepts_list = [
{
"instance_prompt": "photo of zwx dog",
"class_prompt": "photo of a dog",
"instance_data_dir": "/content/data/zwx",
"class_data_dir": "/content/data/dog"
},
# {
# "instance_prompt": "photo of ukj person",
# "class_prompt": "photo of a person",
# "instance_data_dir": "/content/data/ukj",
# "class_data_dir": "/content/data/person"
# }
]
# `class_data_dir` contains regularization images
Aspect Ratio Bucketing
对应上面参数中的 --use_aspect_ratio_bucket。需要在 Colab 中使用的话,aspect_ratio_bucket 调成 enable: true。
Aspect Ratio Bucketing 简称 ARB, 原版训练均只能使用 1:1 的图像,开启 ARB 使得训练非 1:1 的图像成为可能,但并非任意比例尺的图像,不在 bucket 内的图像将会被裁切。
[[ 256 1024], [ 320 1024], [ 384 1024], [ 384 960], [ 384 896], [ 448 832], [ 512 768], [ 512 704], [ 512 512], [ 576 640], [ 640 576], [ 704 512], [ 768 512], [ 832 448], [ 896 384], [ 960 384], [1024 384], [1024 320], [1024 256]]
ARB 与 DreamBooth 一起使用的兼容性不好,仅推荐 Native Training 时使用。
更多内容请查阅 使用 Dreambooth 训练稳定扩散的实验的分析
训练
按照笔记本步骤或说明训练即可,Colab 用户注意挂载磁盘防止断线。
训练完毕要将 diffusers 权重转换为 ckpt 文件才能使用哦!利用类似 diffusers2ckpt.py 的文件即可。
有些脚本提供
--half参数用来保存 float16 半精度模型,权重文件大小会减半(约 2g),但效果基本一致。
WebUi 用户将训练出的 .ckpt 文件复制到 webui 的 models\Stable-diffusion 目录里,在 webui 的左上角切换模型即可使用。
使用时在 prompt 里输入你之前指定的标志符(例如
过拟合后,CFG 影响很大,可以试试降低 CFG.
模型的效果要看测试图。
在 Windows 上使用
这里的内容适用于想在 Windows 系统上进行训练的同学。
来自 [^18]
Windows 上的 Dreambooth 可以采用 ShivamShrirao 的优化版本来节省显存,diffusers/examples/dreambooth by ShivamShrirao.
由于相关链接库的原因,用于在 Linux 上的部署方法无法直接在 windows 上使用,由于同样的原因,该优化版本在 colab 上最低 9.9G 的显存需求在 windows 上应该稍高,因此推荐 至少使用显存 12G 的显卡。
编纂者仅在 16G 显存的机器上测试成功,12G 显存的机器理论可行。
Tip
修改或覆盖原始库中的文件时,请备份。
准备环境 Git , Python , MiniConda (或 MiniConda )。
以下步骤在 python3.8,windows10 22H2 中操作,其他环境未测试
创建工作目录 ,在目录下构建 python3.8 的 venv 虚拟环境
python -m venv --system-site-packages venv_dbwin
venv_dbwin\Scripts\activate
python.exe -m pip install --upgrade pip
克隆 ShivamShrirao 的优化版本 dreambooth 到工作目录中并安装相关依赖(使用的 构建版本, 后续版本可能无法支持本文方法)
git clone https://github.com/ShivamShrirao/diffusers
cd diffusers
pip install -e .
cd examples\dreambooth
pip install -U -r requirements.txt
pip install OmegaConf
pip install pytorch_lightning
pip install einops
pip install bitsandbytes==0.34
完成后,在 windows 上需要根据 这个 Issue 中的方法实现 bitsandbytes 支持
将 这个仓库 中的 libbitsandbytes_cuda116.dll 文件手动拷贝到工作目录下的 venv_diffusers\Lib\site-packages\bitsandbytes 中,位于 libbitsandbytes_cuda116.so 的旁边;
然后更改脚本以应用,可以手动修改,为方便也可以下载以下文件替换:
将 cextension.py - https://pastebin.com/jjgxuh8V 覆盖到 venv_diffusers\Lib\site-packages\bitsandbytes 目录。
将 main.py - https://pastebin.com/BsEzpdpw 覆盖到 venv_diffusers\Lib\site-packages\bitsandbytes\cuda_setup 目录。
安装 PyTorch 和 Torchvision
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
进入 Python 并测试调用
python
>>>import bitsandbytes
如果没有报错证明安装成功( Ctrl + Z 并回车退出 python)。
临时指南
设置 accelerate
accelerate config
In which compute environment are you running? ([0] This machine, [1] AWS (Amazon SageMaker)): 0
Which type of machine are you using? ([0] No distributed training, [1] multi-CPU, [2] multi-GPU, [3] TPU [4] MPS): 0
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]:NO
Do you wish to use FP16 or BF16 (mixed precision)? [NO/fp16/bf16]: fp16
按照上面的设置选项,也就是(0,0,NO,NO,fp16)。
修改显存优化
因为无法使用 xformers ,所以使用 此文件 中的优化方法作为代替。
将 attention.py - https://pastebin.com/nmwTrGB9 覆盖到 diffusers\src\diffusers\models 目录。
至此环境配置完成,可以开始训练了。具体使用参数请查阅 ShivamShrirao 的 readme 文件和 notebook 文件。
Info
我使用以下参数训练。
accelerate launch --num_cpu_threads_per_process 8 diffusers/examples/dreambooth/train_dreambooth.py --pretrained_model_name_or_path=models/diffusers_model --pretrained_vae_name_or_path=models/diffusers_model/vae --output_dir=models --concepts_list="concepts_list.json" --with_prior_preservation --prior_loss_weight=1.0 --seed=1337 --resolution=512 --mixed_precision="fp16" --lr_scheduler="constant" --use_8bit_adam --gradient_accumulation_steps=1 --train_batch_size=1 --max_train_steps=800 --save_interval=10000 --learning_rate=1e-6 --num_class_images=100 --lr_warmup_steps=0 --gradient_checkpointing

峰值显存占用正好为 12G,如果您只有一个显卡,显存不高于 12G,而且同时需要用于 Windows 系统显示,请关闭所有占用显存的程序或网页等,减少额外显存消耗再进行训练。
diffusers 不能直接使用 ckpt 文件进行训练,需要先进行转换,示例如下。
python diffusers\scripts\convert_original_stable_diffusion_to_diffusers.py --checkpoint_path model.ckpt --original_config_file v1-inference.yaml --scheduler_type ddim --dump_path models/diffusers_model
训练完成同样要进行打包转换为 ckpt, 即可用于 AUTOMATIC1111 的 WebUI 中。
python diffusers\scripts\convert_diffusers_to_original_stable_diffusion.py --model_path models/resultModel --checkpoint_path result.ckpt --half
这是一个临时的解决方案,期待 Windows 官方适配的到来。
其他 ...
DreamBooth 参数表
usage: argmark [-h] --pretrained_model_name_or_path
PRETRAINED_MODEL_NAME_OR_PATH [--revision REVISION]
[--tokenizer_name TOKENIZER_NAME] --instance_data_dir
INSTANCE_DATA_DIR [--class_data_dir CLASS_DATA_DIR]
[--instance_prompt INSTANCE_PROMPT]
[--class_prompt CLASS_PROMPT]
[--with_prior_preservation]
[--prior_loss_weight PRIOR_LOSS_WEIGHT]
[--num_class_images NUM_CLASS_IMAGES]
[--output_dir OUTPUT_DIR] [--seed SEED]
[--resolution RESOLUTION] [--center_crop]
[--use_filename_as_label] [--use_txt_as_label]
[--train_text_encoder]
[--train_batch_size TRAIN_BATCH_SIZE]
[--sample_batch_size SAMPLE_BATCH_SIZE]
[--num_train_epochs NUM_TRAIN_EPOCHS]
[--max_train_steps MAX_TRAIN_STEPS]
[--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS]
[--gradient_checkpointing]
[--learning_rate LEARNING_RATE] [--scale_lr]
[--lr_scheduler LR_SCHEDULER]
[--lr_warmup_steps LR_WARMUP_STEPS] [--use_8bit_adam]
[--adam_beta1 ADAM_BETA1] [--adam_beta2 ADAM_BETA2]
[--adam_weight_decay ADAM_WEIGHT_DECAY]
[--adam_epsilon ADAM_EPSILON]
[--max_grad_norm MAX_GRAD_NORM] [--push_to_hub]
[--hub_token HUB_TOKEN] [--hub_model_id HUB_MODEL_ID]
[--logging_dir LOGGING_DIR]
[--log_with {tensorboard,wandb}]
[--mixed_precision {no,fp16,bf16}]
[--local_rank LOCAL_RANK]
[--save_model_every_n_steps SAVE_MODEL_EVERY_N_STEPS]
[--auto_test_model] [--test_prompt TEST_PROMPT]
[--test_prompts_file TEST_PROMPTS_FILE]
[--test_negative_prompt TEST_NEGATIVE_PROMPT]
[--test_seed TEST_SEED]
[--test_num_per_prompt TEST_NUM_PER_PROMPT]
Arguments
英文说明在英文页面。
| short | long | default | help |
|---|---|---|---|
-h |
--help |
显示此帮助信息并退出 | |
--pretrained_model_name_or_path |
None |
预训练模型的路径或来自 huggingface.co/models 的模型标识符。 | |
--revision |
None |
修订来自 huggingface.co/models 的预训练模型标识。 | |
--tokenizer_name |
None |
预训练的标记器名称或路径,如果与 model_name 不相同的话。 | |
--instance_data_dir |
None |
一个包含实例图像训练数据的文件夹。 | |
--class_data_dir |
None |
一个包含类图像训练数据的文件夹。 | |
--instance_prompt |
None |
带有指定实例的标识符的提示 | |
--class_prompt |
None |
提示指定与提供的实例图像相同类别的图像。 | |
--with_prior_preservation |
标记,以增加先前的保存损失。 | ||
--prior_loss_weight |
1.0 |
The weight of prior preservation loss. | |
--num_class_images |
100 |
用于事先保存损失的最小的类图像。如果没有足够的图像,额外的图像将用 class_prompt 进行采样。 | |
--output_dir |
text-inversion-model |
输出目录,模型预测和 checkpoints 将被写入该目录。 | |
--seed |
None |
可重复的培训的种子。 | |
--resolution |
512` | 输入图像的分辨率,训练/验证数据集中的所有图像将被调整到这个分辨率。 | |
--center_crop |
是否在调整图像大小至分辨率前居中裁剪图像? | ||
--use_filename_as_label |
使用文件名作为图像标签而不是 instance_prompt,在训练图像差异较大的样式时对正则化很有用 | ||
--use_txt_as_label |
使用 filename.txt 文件的内容作为图像标签而不是 instance_prompt,在训练图像差异较大的样式时对正则化很有用 | ||
--train_text_encoder |
是否训练文本编码器 | ||
--train_batch_size |
4 |
训练数据加载器的批量大小(每个设备)。 | |
--sample_batch_size |
4 |
采样图像的批量大小(每个设备)。 | |
--num_train_epochs |
1 |
None |
|
--max_train_steps |
None |
要执行的训练步骤总数。 如果提供,则覆盖 num_train_epochs。 | |
--gradient_accumulation_steps |
1 |
执行向后/更新传递之前要累积的更新步数。 | |
--gradient_checkpointing |
是否使用梯度检查点来以较慢的反向传递为代价来节省内存。 | ||
--learning_rate |
5e-06 |
要使用的初始学习率(在潜在的预热期之后)。 | |
--scale_lr |
通过 GPU 数量、梯度累积步长和批量大小来缩放学习率。 | ||
--lr_scheduler |
constant |
The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"] | |
--lr_warmup_steps |
500 |
lr 调度程序中预热的步骤数。 | |
--use_8bit_adam |
是否使用 bitsandbytes 中的 8 位 Adam。 | ||
--adam_beta1 |
0.9 |
Adam 优化器的 beta1 参数。 | |
--adam_beta2 |
0.999 |
Adam 优化器的 beta2 参数。 | |
--adam_weight_decay |
0.01 |
要使用的权重衰减。 | |
--adam_epsilon |
1e-08 |
Adam 优化器的 Epsilon 值 | |
--max_grad_norm |
1.0 |
最大梯度范数。 | |
--push_to_hub |
是否将模型推送到 Hub。 | ||
--hub_token |
None |
用于推送到模型中心的令牌。 | |
--hub_model_id |
None |
要与本地 output_dir 保持同步的存储库名称。 |
|
--logging_dir |
logs |
TensorBoard log directory. Will default to output_dir/runs/ CURRENT_DATETIME_HOSTNAME**. | |
--log_with |
tensorboard |
None |
|
--mixed_precision |
no |
是否使用混合精度。 在 fp16 和 bf16 (bfloat16) 之间选择。 Bf16 需要 PyTorch >= 1.10 和 Nvidia Ampere GPU。 | |
--local_rank |
-1 |
对于分布式训练:local_rank | |
--save_model_every_n_steps |
None |
None |
|
--auto_test_model |
保存后是否自动测试模型 | ||
--test_prompt |
A photo of a cat |
用于测试模型的提示。 | |
--test_prompts_file |
None |
包含用于测试模型的提示的文件。示例:test_prompts.txt,每一行都是一个提示 | |
--test_negative_prompt |
`` | 用于测试模型的否定提示。 | |
--test_seed |
42 |
用于测试模型的种子。 | |
--test_num_per_prompt |
1 |
每个提示生成的图像数量。 |